* 모든 실습은 mac의 환경에 맞게 수정하며 clone된 파일 외에는 직접 작성해보며 실습해 실제 실습파일 구조나 코드가 다를 수 있습니다.
* 해당 글은 실전! 프로젝트로 배우는 딥러닝 컴퓨터비전을 토대로 정리한 글이므로 꼭 해당 책을 구매해 읽어보길 권장한다.
합성곱 심층 신경망 (= CNN, Convolution Neural Network)
- 영상의 특징을 매우 정확하게 추출하여 영상 분석에 아주 성공적으로 활용할 수 있는 방법론
- 합성곱 + 딥러닝
- 합성곱 (= Convolution)
- 이미지 프로세싱 분야에서 매우 일반적인 기술
- 입력을 목적에 따라 가공해서 원하는 출력을 얻기 위해 사용하는 연산 [1]
- 합성곱 (= Convolution)
- 입력 데이터가 3차원 데이터의 경우, 커널의 크기의 마지막 차원이 항상 입력 데이터의 색상 차원과 동일해야 한다.
- ex) 흑백 이미지일때, 마지막 차원 = 1 / 컬러 이미지일때, 마지막 차원 = 3
- 특징 맵 (=Feature Map) : 원본 이미지의 특징을 추출해 가지고 있는 활성화 맵
- In 1 layer, 커널을 다수 사용 => 커널의 개수와 동일한 활성화 맵 산출 => 특징 맵 (Feature Map) 생성
- 도입부 : 큰 사이즈, 윤곽선 등의 특징 보유
- 중반부 : 중간 사이즈, 얼룩무늬 등 패턴 특징 보유
- 후반부 : 작은 사이즈, 눈/바퀴 등 구체적인 특징 보유
FC layer (= Fully Connected layer, Affine layer)
- 여러 층으로 중첩된 행렬곱의 식
- y=W⋅x+b
- 입력 데이터와 출력 데이터는 모두 1차원이여야 한다.
- 문제점 : 데이터의 형상 무시한다. 즉, 이미지 데이터의 경우 공간적 정보를 살릴 수 없다.
- 이미지 데이터의 경우 공간적 정보를 살릴 수 없다 = 공간적으로 가까운 픽셀은 값이 비슷하거나, RGB의 각 채널은 서로 밀접하게 관련되어 있거나, 거리가 먼 픽셀끼리는 별 연관이 없는 등 3차원 속에서 의미를 갖는 본질적인 패턴이 숨어있는데 이를 살릴 수 없다. [2]
Conv layer
- 콘볼루션 계산을 하는 레이어
- 목적 : 이미지의 공간 정보를 잃지 않고 이미지의 특징을 추출해 대상을 인지할 수 있는 인공지능 = 인간의 눈 역할
- 이미지 데이터 뿐만 아니라 다양한 형태의 데이터에서 원하는 특성을 추출하는데 탁월함. => 신호처리나 음성인식 분야에서도 활용
- 연산 방식
- 입력 크기 : (H,W)
- 출력 크기 : (OH, OW)
- 필터(=커널) 크기 : (FH, FW)
- 패딩 : P
- 스트라이드(=커널이 공간 이동하는 사이즈) : S



- 산출물 : 활성화 맵
- 활성화 맵(=Activation Map) : 컨볼루션 연산을 하는 과정에서 'Dot Product'가 생성되고, 커널이 위치 이동하며 여러 번의 컨볼루션 연산을 해 생성된 'Dot Product'들의 집합.
- 연산 방식
- 활성화 맵 : (W2,H2)
- 입력 : (W1,H1)
- 커널 : F
- 스트라이드 : S
- 패딩 : P



Pooling layer
- 계산없이 사이즈를 줄이는 것 (=다운샘플링)
- 각 활성화 맵에서 독립적으로 작동
- 종류 : 최소, 최대(=주로 이용), 평균 등

LeNet(CNN) MNIST 실습
class Net(nn.Module): # 2개 conv layer, 2개 fc layer
def __init__(self):
super().__init__()
self.conv1=nn.Conv2d(1,10,kernel_size=5)
self.conv2=nn.Conv2d(10,20,kernel_size=5)
self.conv2_drop=nn.Dropout2d()
self.fc1=nn.Linear(320,50)
self.fc2=nn.Linear(50,10)
def forward(self,x):
x=F.relu(F.max_pool2d(self.conv1(x),2))
x=F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)),2))
x=x.view(-1,320)
x=F.relu(self.fc1(x))
x=self.fc2(x)
return F.log_softmax(x,dim=1)
device = torch.device('mps' if torch.backends.mps.is_available() else "cpu") # gpu 사용
model=Net().to(device) # 네트워크 정의
optimizer=optim.SGD(model.parameters(),lr=0.01) # 최적화 함수 # 경사하강법 사용, 학습률 0.01
data, target=next(iter(train_loader)) # 훈련 배치 데이터 로드 및 변수 준비
def fit(epoch, model, data_loader, phase='training',volatile=False):
if phase=='training':
model.train()
if phase=='validation':
model.eval()
volatile=True # 역전파 계산 x # torch.no_grad() 로 대체됨.
running_loss=0.0
running_correct=0
for batch_idx, (data,target) in enumerate(data_loader):
if device:
data, target = data.to(device), target.to(device)
data, target=Variable(data,volatile), Variable(target)
if phase=='training':
optimizer.zero_grad()
output=model(data)
loss=F.nll_loss(output,target) # nll 손실함수 사용 # 로그확률을 입력으로 받음.
running_loss+=F.nll_loss(output,target,reduction='sum').item()
preds=output.data.max(dim=1,keepdim=True)[1]
running_correct+=preds.eq(target.data.view_as(preds)).cpu().sum()
if phase=='training':
loss.backward()
optimizer.step()
loss=running_loss/len(data_loader.dataset)
accuracy=100. * running_correct/len(data_loader.dataset)
print(f'{phase} loss is {loss:{5}.{2}} and {phase} accuracy is {running_correct}/{len(data_loader.dataset)}{accuracy:{10}.{4}}')
return loss,accuracy
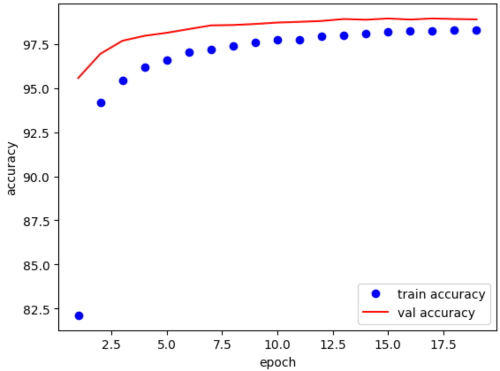
Reference
[2] "밑바닥부터 시작하는 딥러닝", 사이토 고키, p229
'Book > 실전! 프로젝트로 배우는 딥러닝 컴퓨터비전' 카테고리의 다른 글
| Part1-4. 딥러닝 영상분석 (7) | 2025.01.06 |
|---|---|
| Part1-1. 딥러닝 모델 기본 구조 (5) | 2025.01.05 |
| [횡단보도 보행자 보호 시스템 프로젝트] 캐시 파일 오류 해결 및 yolov7 결과 (6) | 2025.01.03 |
| [횡단보도 보행자 보호 시스템 프로젝트] 데이터 분할 오류 해결 및 yolov5 결과 (1) | 2025.01.02 |
| [횡단보도 보행자 보호 시스템 프로젝트] 개요 설치 및 데이터 준비 (4) | 2024.12.29 |